Kafka standard deployment
A standard Kafka deployment consists of brokers, a zookeeper, producers, and consumers, as shown in the following figure:

Standard Kafka deployment
Brokers
A typical Kafka cluster consists of multiple brokers whose purpose is to maintain load balance. Kafka brokers are stateless; they use Zookeeper for maintaining the cluster state. A single broker instance can handle hundreds of thousands of read and write operations per second. In terms of data size, each broker can handle terabytes of messages without a performance impact. You can perform broker leader election through Zookeeper.
Zookeeper
The Zookeeper service is a tool for managing and coordinating Kafka brokers. The purpose of Zookeeper is to:
- Handle topic-related information, for example, the number of existing topics, partitions within each topic, topic replication information, and so on.
- Track broker status, for example, the broker is the cluster leader, the brokers that are functional or are leaving or joining the cluster, and so on.
Zookeeper structure is similar to that of a distributed file system. However, each Zookeeper node can have children nodes as well as data associated with it, as shown in the following example:
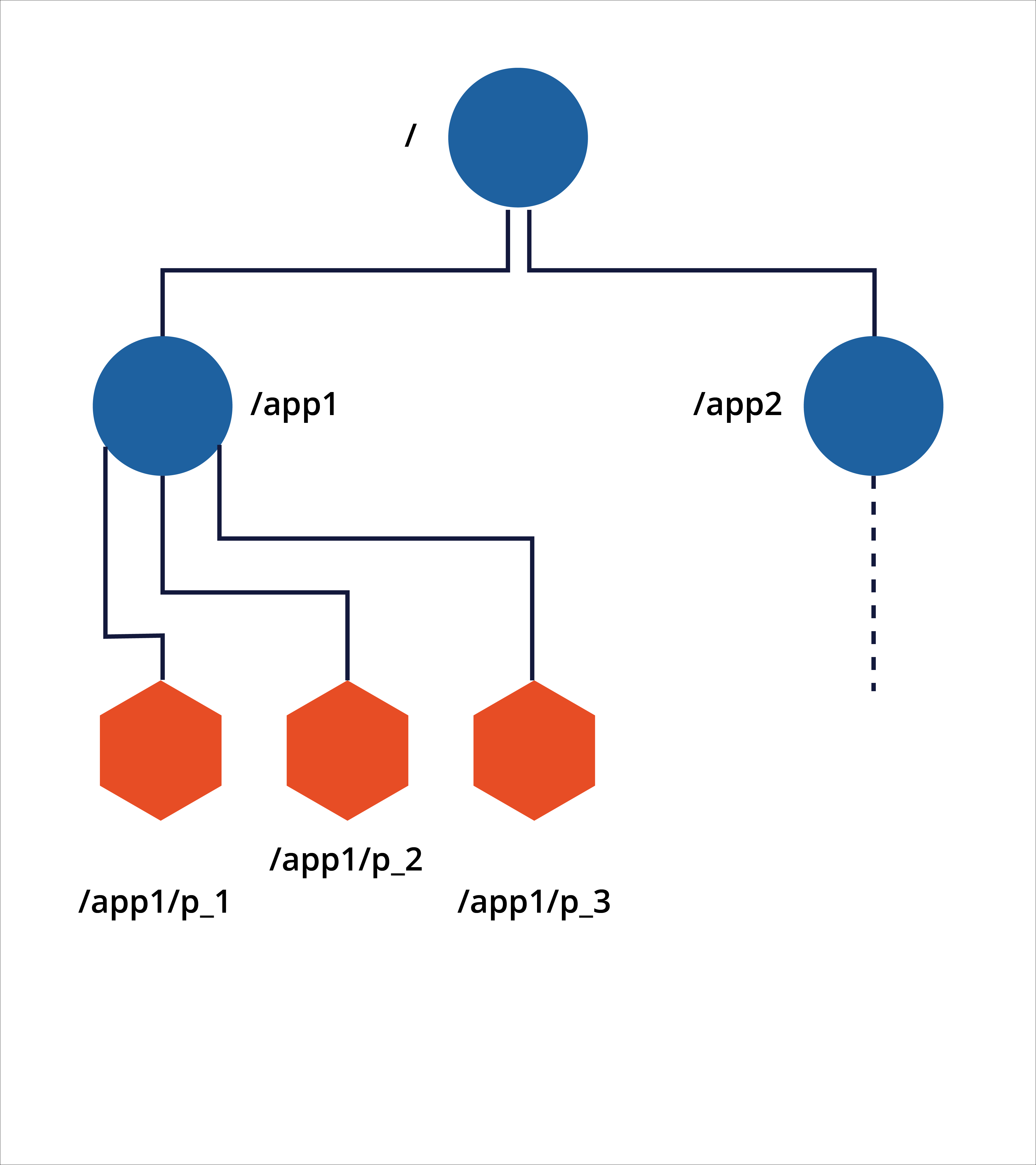
Zookeeper nodes
The following figure presents a simplified example of a Kafka-related schema that is stored in Zookeeper:
Consider the following from the example above:
- /brokers/ids – Keeps the data of the active brokers.
- /brokers/ids/15 – This is the description of the broker with ID 15. The broker address is 10.31.1.146:9107.
- /brokers/ids/30 – This is the description of the broker with ID 30. The broker address is 10.31.1.146:9122.
- /brokers/topics – Keeps the information about all existing topics within the cluster. Currently, only one topic /brokers/topics/KafkaDataSet is defined. The topic has two partitions, one on broker 15, the other one on broker 30.
- /controller – Keeps the information about the leader broker in the cluster. The current leader is broker 15.
- Ephemeral nodes are marked pink in the example above.
Ephemeral nodes
The Zookeeper nodes can be of type persistent and ephemeral.
Ephemeral nodes exist as long as the broker session that created the node is active. When the session ends the node is deleted. This means that when a broker stops, the information about that broker is removed from /brokers/ids/ parent node. If that broker was the leader, the /controller node is also removed.
Zookeeper tracks sessions state using heartbeat: if no heartbeats are received Zookeeper invalidates the session and removes all the ephemeral nodes of the session.
Watches
The Zookeeper has concept of watches. A watch event is one-time trigger that is sent to the client that set the watch, which occurs when the data for which the watch was set changes.
In practice, this means that if Kafka broker wants to receive an update in case the specific node has changed or children node changes, it sets a watch for the node in question.
Producers
Producers push data to brokers. When a broker is started, all producers automatically search for it and send a message to that broker. Producers do not wait for a response from the broker and send messages as fast as the broker can handle.
Consumers
Because Kafka brokers are stateless, the consumer must establish the number of consumed messages by using the partition offset. If the consumer acknowledges a particular message offset, it implies that the consumer has consumed all prior messages. The consumer issues an asynchronous pull request to the broker to have a buffer of bytes ready to consume. The consumers can rewind or skip to any point in a partition simply by supplying an offset value. The consumer is notified by the offset value by Zookeeper.
Integration considerations
Unlike Apache Cassandra or other decentralized systems, Kafka requires at least two clusters: a broker cluster and a Zookeeper cluster. To manage Kafka cluster automatically, you need to manage both brokers and Zookeeper. Kafka cannot function properly without a Zookeeper cluster, which is consistent configuration storage.
You can substitute Zookeeper with a Pega database as configuration storage to make it suitable for automatic management.
To view the main outline for this article, see Kafka as a streaming service.
Previous topic Kafka operations Next topic Kafka with Charlatan