Working with HBase data sets on the Pega 7 Platform
The decision management functionality of the Pega 7 Platform provides you with the capability to connect to an external HBase data set for dynamic, real-time read and write operations on high-volume data. This tutorial provides an overview of the HBase data model, as well as of the common operations that you can perform on an HBase data set in the Pega 7 Platform.
- The HBase data model
- Previewing the HBase data
- Mapping the HBase data
- Performing the run operation on an HBase data set
The HBase data model
In the HBase data store, tables are organized by column instead of by row. The columns are organized in column family groups. The HBase data model is a sparse, distributed, and persistent multidimensional sorted map. HBase data is indexed by row key, column key, and time stamp. After you connect to an external HBase data set, you can read, modify, and adapt data from the Pega 7 Platform. The HBase data model consists of the following elements:
- Table - HBase organizes data into tables. Table names are strings and are composed of characters that are safe to use in the file system path.
- Row - Within a table, data is stored in rows. Rows are identified uniquely by their key values. Row keys do not have a data type and are always treated as bytes.
- Column Family - Data within a row is grouped by column family. Column families also affect the physical arrangement of data stored in HBase. For this reason, the column families must be defined in advance. Every row in a table has the same column family. A row does not have to store data in all its families. Column families are strings and are composed of characters that are safe to use in a file system path.
- Column Qualifier - The data within a column family is addressed by its column qualifier. Column qualifiers do not have to be specified when the table is created. Column qualifiers do not have to be consistent between rows. Like row keys, column qualifiers do not have a data type and are always treated as bytes.
- Cell - The unique identifier of a cell consists of a combination of a row key, a column family, and a column qualifier. The data stored in a cell is referred to as a cell value. Cell values do not have a data type and are always treated as bytes.
- Time stamp - Values within a cell are versioned. Each version is identified by its number, which by default is the time stamp of when the cell was written. If a time stamp is not specified during the write operation, the current time stamp is used. If the time stamp is not specified for the read operation, the latest time stamp is returned. The number of cell value versions retained by HBase is configured for each column family. The default number of cell versions is three.
Previewing the HBase data
To preview data with the HBase data set, the system uses the Browse and Browse by keys operations. The Browse operation returns all records from the HBase data source. The Browse by keys operation retrieves only specific records.
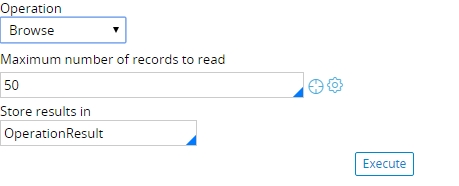
Browse operation
For detailed steps about how to preview HBase data, see DataSet-Execute method.
Mapping the HBase data
You use the property mapping functionality of the Pega 7 Platform to associate data fields received from an external database with properties or other sources or destinations in the Pega 7 Platform.
- Open an instance of the HBase data set.
- Make sure that the Pega 7 Platform is connected to the target Hadoop instance. In the Connection section, click Test connectivity to verify the connection.
- In the Mapping section, in the HBase table name field, select a database table.
- Select a Row ID from the selected HBase table.
- Optional: Click Preview table to inspect the selected table.
The preview functionality allows you to view the first 100 row IDs and all the column families that are defined in the table schema and makes defining property mapping easier.
- Click and perform the following actions:
- In the HBase column field, specify the name of a column in the HBase data set.
- In the Property Name field, specify the Pega 7 Platform property that you want to map to the column.
- Repeat this step for all the columns that you want to map.
- Click Save.
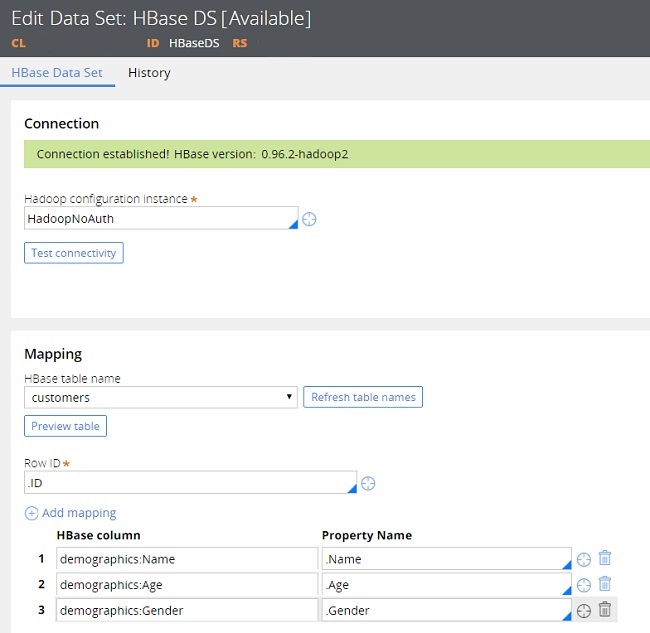
Data set details
Performing the run operation on an HBase data set
You can perform the following run operations on an HBase data set:
- Save - Stores the step page or the referred pagelist with a specific mapping to the HBase data set.
- Browse by keys - Loads a specific record from the HBase data set into the Pega 7 Platform.
- Browse - Returns all the records from the HBase data set.
- Delete by keys - Removes a single row in the HBase data set.
- Truncate - Disables and re-creates a table in the HBase data set.
- Open an HBase data set instance on the Pega 7 Platform.
- Click . The Test page is displayed:
- On the Test page, expand the Operation menu and select one of the available operations.
- Click Run.
For more information, see DataSet-Execute method.
Previous topic Defining Hadoop records Next topic Working with HDFS data sets on the Pega 7 Platform