Data flow run priorities
Use the data flow service to protect the system against running out of resources. The data flow service can automatically queue and execute data flow runs according to configured priorities that indicate the relative importance of each run. For example, you can set the priority of an important data flow run to High to ensure that it will be performed first.
To protect the system from running out of resources due to a large number of data flows that run simultaneously, you can indicate the maximum number of data flow runs for a given node type, as well as change the maximum active runs threshold at run time. For more information, see Data flow run limits.
By setting data flow priorities, you can specify the importance of each data flow in a given data flow service type. Data flows are executed automatically, according to two factors:
- The relative importance (priority) of the run that you can set to Low, Medium, or High.
- The order of submission (activation time) of the run.
The runs that cannot execute when triggered by the user or system event (for example, low priority runs or runs that exceed the set data flow service limit) are queued automatically. The data flow service attempts to schedule the queued runs of equal priority in the order of submission, from the earliest to the latest. When the resources become available, then the oldest highest priority run starts. If the run is completed, stopped, or fails, then the current oldest run with the highest priority moves to the front of the queue. If the data flow service can perform a run with a higher priority, then the lower priority runs will remain queued.
Consider a scenario where the data flow service limit is set to five runs and all runs are currently in progress.

- The data flow service analyzes the run priority first, and then analyzes its
activation time. When the limit of five active runs is reached, a new run (DF-6)
with a medium priority level starts instead of the DF-2 run which has the lowest
priority and has been added most recently. Another newly added run (DF-7) has a
low priority level, therefore the run is queued.
New data flow runs are added to the queue 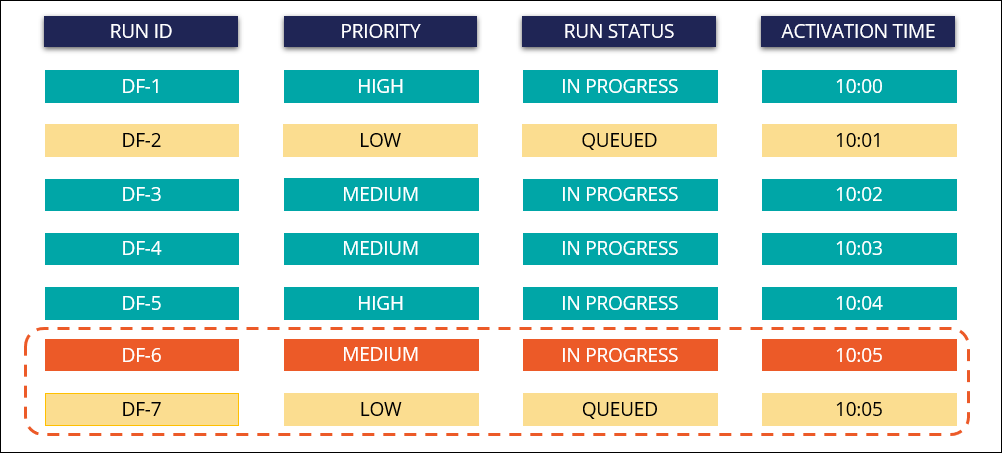
- If you add another run with a higher priority (DF-8), that run starts first,
while the DF-6 run moves to the queue.
Automatic prioritization of a high priority run in the queue 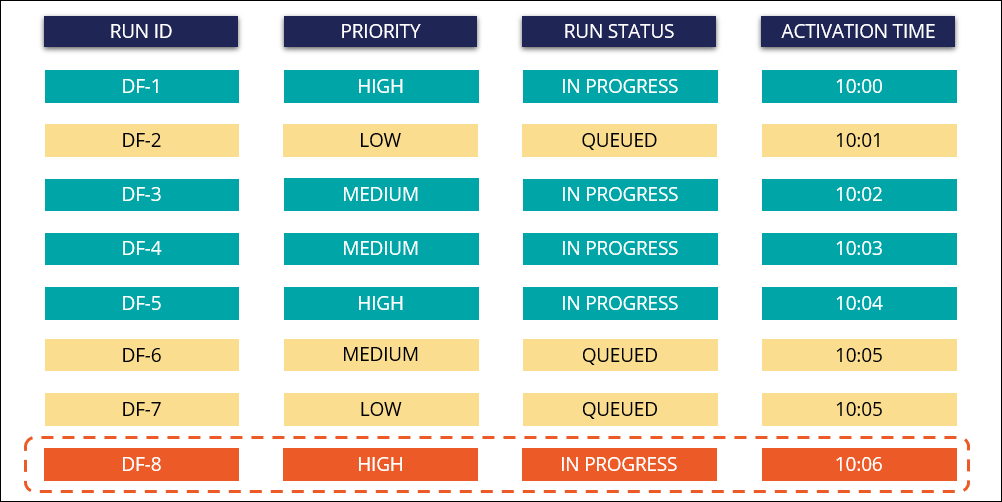
- When the highest priority active run finishes (DF-3), the data flow service
automatically starts the next highest priority, earliest run from the queue
(DF-6).
Completion of the previous runs allows previously queued runs to proceed 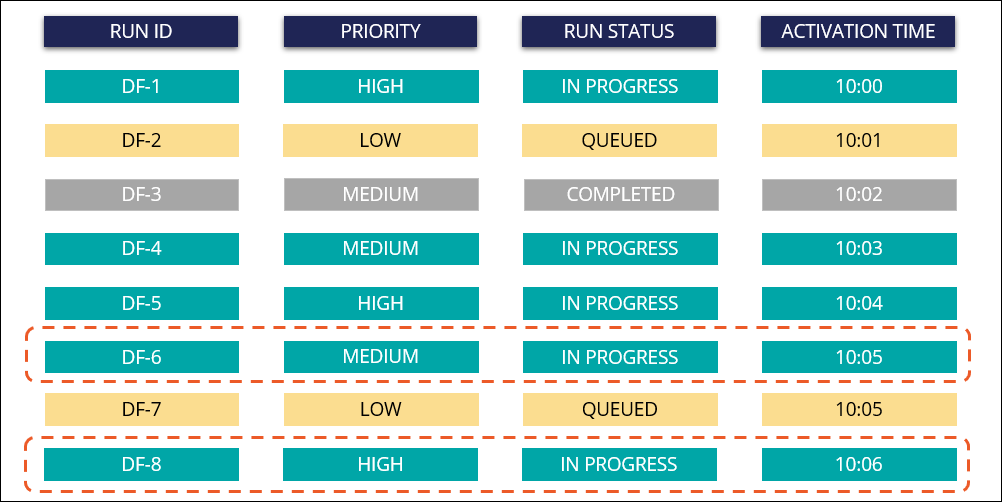
Previous topic Limiting active data flow runs Next topic Prioritizing data flow runs