Creating a File data set record for files on repositories
To import and export CSV or JSON files to and from Pega Platform, create a File data set that references a repository, and then use that data set in the source or destination shape in a data flow.
You can perform the following operations for File data sets referencing a remote repository:
- Browse
- Retrieves records in an undefined order.
- Save
- Saves records to multiple files, along with a meta file that contains the name, size, and the number of records for every file. The Save operation is not available for manifest files.
- Truncate
- Removes all configured files and their meta files, except for the manifest file.
- GetNumberOfRecords
- Estimates the number of records based on the average size of the first few records and the total size of the data set files.
- On the New tab, in the File location section, click Files on repository.
- In the Configuration section, select the source repository:
- To select one of the predefined repositories, click the Repository configuration field, press the Down Arrow key, and choose a repository.
- To create a repository, click the Target icon to the right of the Repository Configuration field, and then perform Creating a repository.
- In the Path section, select how you want to define the files to
import or export:
Choices Actions Define a single file or a range of files - Select Use a file path to import or export data.
- In the File path field, enter the file location.
When importing data, you can match multiple files in a folder by using an asterisk (*) as a wild card character.
When exporting data, you can define a file name that consists of a prefix and an optional date and time pattern by adding a Java SimpleDateFormat string to the file path. The SimpleDateFormat does not support the following characters: "?*<>|:When a file is created, a unique ID is appended to the file name to ensure file uniqueness.For more information, see File Data Set file path pattern.
Define multiple files that you list in a manifest file - Select Use a manifest file to import data.
For manifest files, use the following
.xmlformat: - In the Manifest file path field, enter the location of
the manifest file.
Repository and file path configuration example 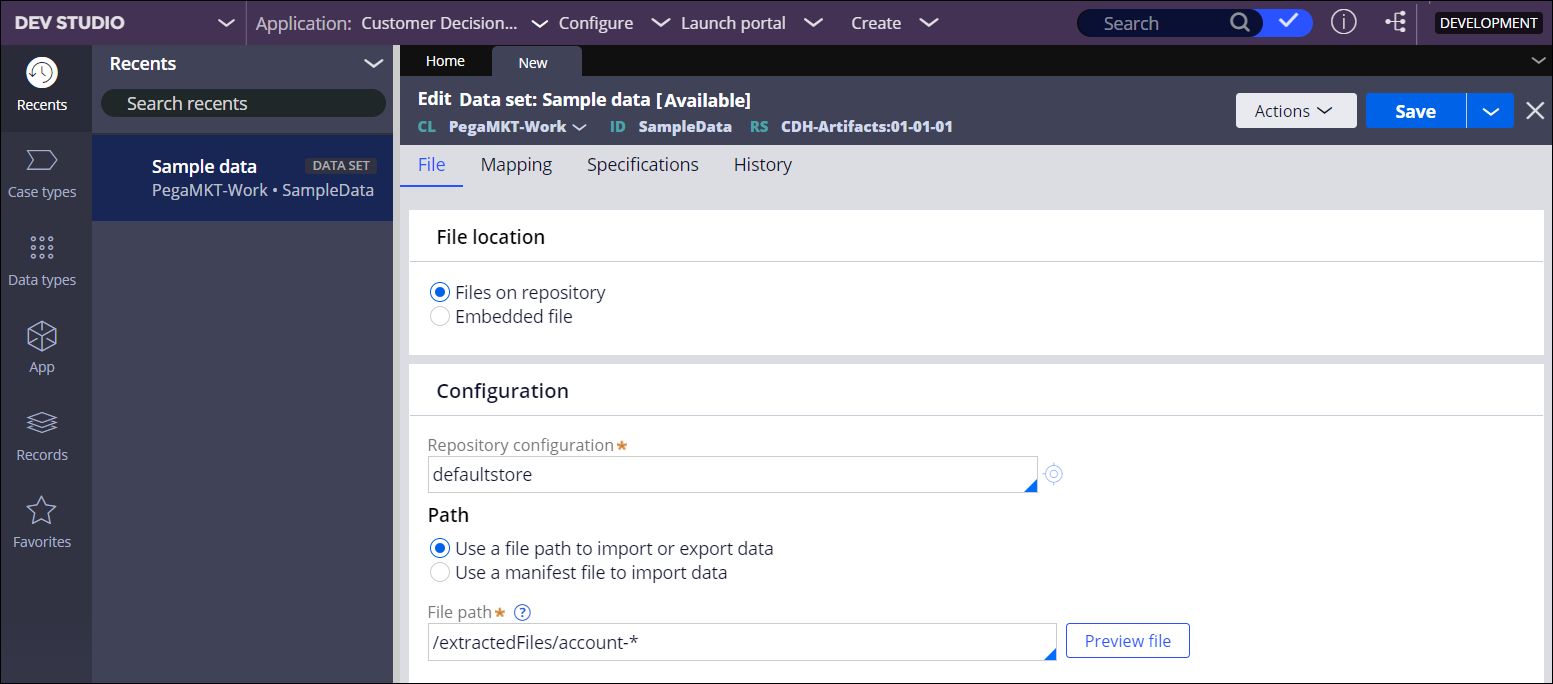
- Optional: Click Preview file.
- In the Data protection section, select Enable data
protection checkbox and provide the Pretty Good Privacy (PGP) keys to
encrypt and decrypt files:
- In the Public key reference field, enter the public key required to encrypt files, for example when exporting data.
- In the Private key reference field, enter the private key required to decrypt files, for example when importing data.
- Optional: In the Passphrase reference field enter the passphrase to decrypt files.
While providing the PGP keys, use the global resource settings syntax:=D_PageName.PropertyName=Declare_PageName.PropertyName
- Optional: If the file is compressed, in the File configuration section,
select Enable file compression, and then select the
Compression type.The supported compression types are
.zipand.gz(gzip). - Optional: To provide additional file processing for read and write operations, such as encoding
and decoding, define and implement a dedicated interface:
- Select Enable custom stream processing.
- In the Java class with reader implementation field, enter the fully qualified name of the java class with the logic that you want to apply before parsing.
- In the Java class with writer implementation field, enter the fully qualified name of the java class with the logic that you want to apply after serializing the file, before writing it to the system.
For more information on the custom stream processing interface, see Requirements for custom stream processing in File data sets. - From the File type drop-down list, select the type of file that you want to import or export with this data set, CSV or JSON.
- Optional: For CSV files, to update the settings automatically, click Configure automatically, and then go to step 12.
- For CSV files, update additional file settings:
- Specify if the file contains a header row by selecting the File contains header checkbox.
- In the Delimiter character list, select a character separating the fields in the selected file.
- In the Supported quotation marks list, select the quotation mark type used for string values in the selected file.
- For CSV and JSON files, update date and time settings:
- In the Date Time format field, enter the pattern
representing date and time stamps in the selected file.The default pattern is: yyyy-MM-ddHH:mm:ss
- In the Date format field, enter the pattern representing
date stamps in the selected file.The default pattern is: yyyy-MM-dd
- In the Time Of Day format field, enter the pattern
representing time stamps in the selected file.The default pattern is: HH:mm:ss
- In the Date Time format field, enter the pattern
representing date and time stamps in the selected file.
- For CSV files, in the Mapping tab, modify the number of mapped
columns:
- To add a CSV file column, click Add mapping.
- To remove a CSV file column and the associated property mapping, click Delete mapping for the applicable row.
- For CSV files, on the Mapping tab, check and complete the
mapping between the columns in the CSV file and the corresponding properties in Pega Platform:
- To map an existing property to a CSV file column, in the Property column, press the Down Arrow and choose the applicable item from the list.
- For CSV files with a header row, to automatically create properties that are not in Pega Platform and map them to CSV file columns, click Create missing properties. Confirm the additional mapping by clicking Create.
- To manually create properties that are not in Pega Platform and map them to CSV file columns, in the Property column, enter a property name that matches the Column entry, click the Target icon, and configure the new property. For more information, see Creating a property.
- Confirm the new File data set configuration by clicking Save.
- File Data Set file path pattern
To process data in parallel by using multiple threads, the File Data Set operates on a collection of files instead of a single file. The file path pattern includes tokens that match existing files to the pattern or generate new files.
Previous topic Creating a File data set record for embedded files Next topic File Data Set file path pattern