Ingesting customer data into Pega Customer Decision Hub on Pega Cloud
This content applies only to Pega Cloud environments
To make the best, most relevant next-best-action decisions, Pega Customer Decision Hub needs to have up-to-date data about your customers, their demographics, product holding, activity data, and other information that may be stored in third-party systems.
Because this information is updated frequently, you must ensure that the updates propagate to Pega Customer Decision Hub. Not all data is updated at the same frequency. Based on the frequency of updates, customer data can be classified as:
- Non-volatile data
- For example, data attributes which are updated at regular intervals, such as on a weekly or monthly basis.
- Volatile data
- For example, real-time transactional updates, mobile and web transactions, and tags and deletions of customer records, which are updated in real time.
This article covers the mechanism to propagate updates to non-volatile data to Pega Cloud in the process that is known as data ingestion or import. For volatile data, create separate services that propagate updates in real time to ensure optimum results.
A key design principle to follow is that customer data required by Pega Customer Decision Hub should be available at rest. Avoid attempting to make real-time access at the time of making a next-best-action decision as this can substantially impact performance.
Understanding the ingestion process
Before ingesting customer data into Pega Cloud, ensure that the required data is extracted from the data stores and transformed into a structure that matches the customer data model as defined in the context dictionary. This article assumes that the data to be ingested into Pega Cloud is available in a CSV or JSON file format.
The following Pega Platform capabilities are used in the data ingestion process:
- Pega Cloud SFTP service
- To securely transfer files between your enterprise and your Pega applications that Pega Cloud services runs. The service uses the Pega Cloud File Storage repository for reliable and resilient storage. For more information, see .
- Pega Cloud File Storage
- To store the files on Pega Cloud. For more information, see .
- File listeners
- To monitor the files and initiate the data processing. For more information, see Using file listeners.
- Data flows
- To ingest data. For more information, see Processing data with data flows.
- Pega cases
- To orchestrate the end-to-end data ingestion process. Also, to meet additional requirements for auditing, reporting, error tracking, and to retry in case of failure. For more information, see Introduction to case management.
Three types of files are involved in the data ingestion process:
- Data files
- Files that contain customer data and are generated by your extraction-transformation-load (ETL) team.
- Manifest files
- Files that contain metadata about the data files being transferred.
- Token files
- Files that are used to signal that the data file transfer is complete.
For more information, see File types used in data ingestion.
The process starts when the data files and a manifest file are uploaded through the SFTP service into their respective directories in the Pega Cloud repository. A file listener that is configured to listen for the arrival of the manifest file runs a preprocessing check that validates the uploaded files against a manifest file. You can configure the manifest file to contain the file path and file-related metadata, such as information about the files to process, the total record count, and the number of records in each file, as well as the process type of the case that manages the ingestion process. If the preprocessing check passes, the file listener triggers the data ingestion.
Depending on your business requirements, you can configure several data flows to manage the data ingestion. In the following example, a staging data flow runs and ingests the data from the repository to a staging data set. After the data flow run, a postprocessing check validates the ingested data against the manifest file. If the validation passes, the data ingestion is considered successful. A second data flow runs and ingests the files from the staging data set to the core data set.
The following figure shows the main components, such as a file listener and data flows, that support the data ingestion process:
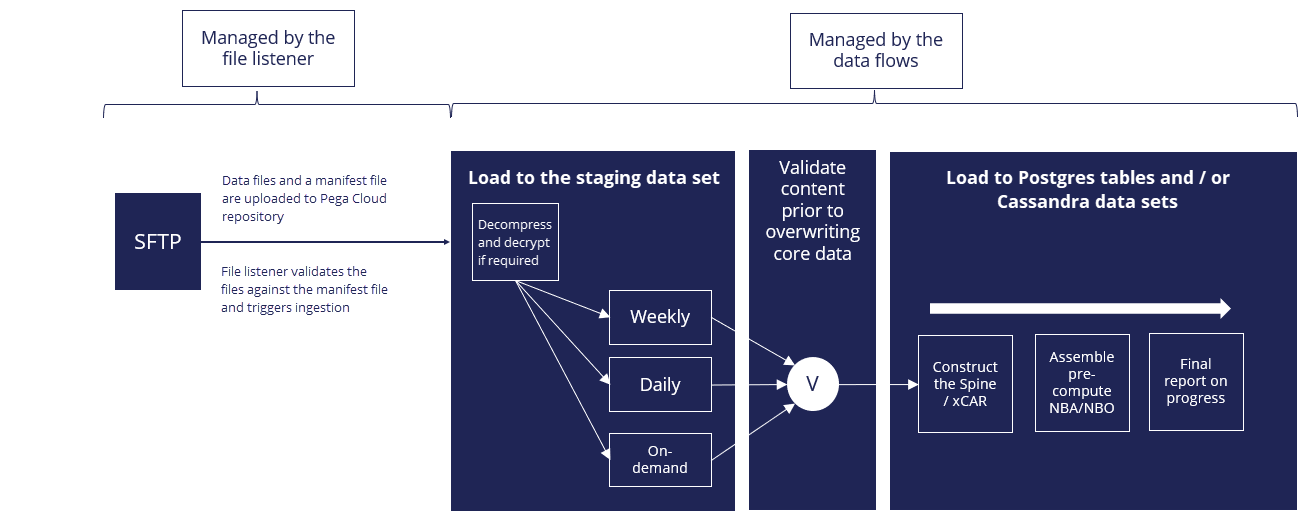
The following figure shows a more detailed workflow of data ingestion, including the use of a manifest file to validate the transferred files.
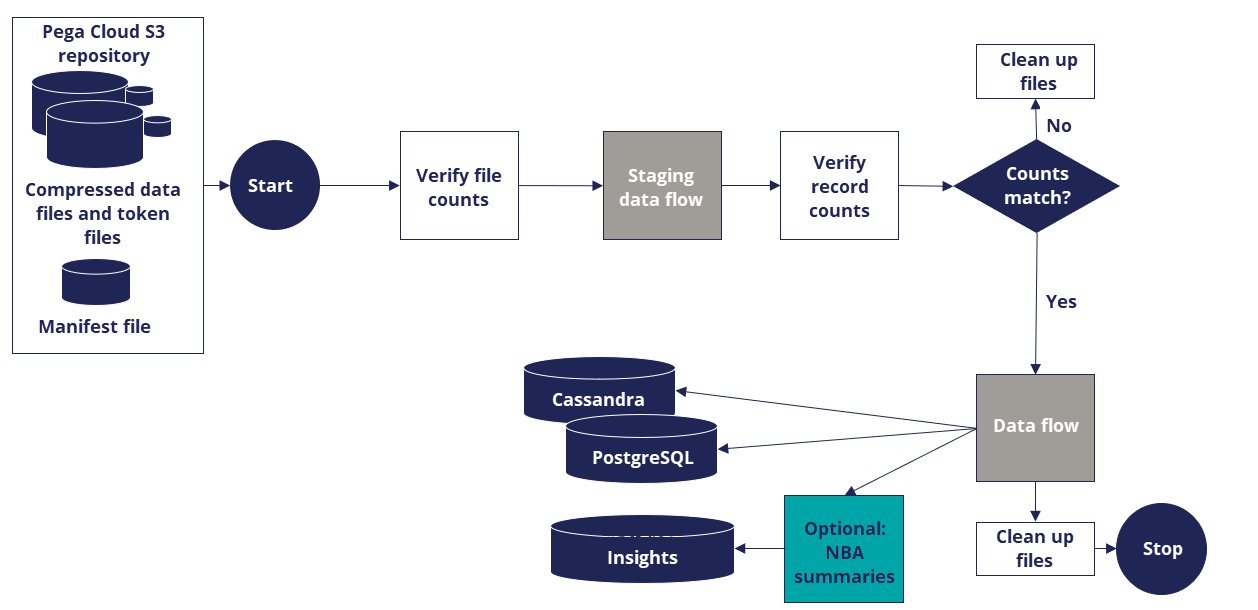
For a sample end-to-end implementation of the process, see Configuring the data ingestion process.
Previous topic Configuring the prospect class Next topic File types used in data ingestion