Claim file processing
The claim file processing follows 3 steps, the first is the receipt and processing of the file, the second is the parsing of the transactions in the file and the third is the creation of a claim work object for processing. The SCE supports the 837 EDI and XML as claim files. The 837 EDI file can be a batch or single claim and the 837 XML is a single claim per file.
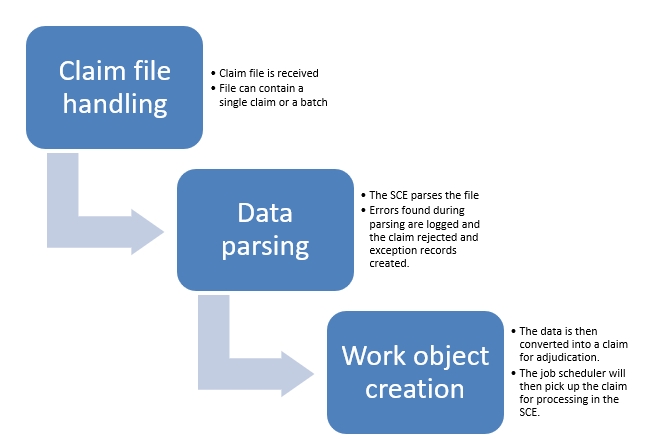
Configuration for file processing
The SCE has a configuration for the file listeners that are used for handling the files that are submitted for processing. Each file listener will need to be configured appropriately in the implementation to support the local infrastructure settings.
| Transaction Type | File Listener |
| X12 5010 837 EDI Professional Claim | X12EDIListener |
| X12 5010 837 EDI Institutional Claim | X12EDIListener |
| X12 5010 837 EDI Dental Claim | X12EDIListener |
| X12 5010 837 XML Professional Claim | CEFileListener |
| X12 5010 837 XML Institutional Claim | CE837IFileListener |
| X12 5010 837 XML Dental Claim | CE837DentalXMLListener |
Key file listener settings
The table below covers the key file listener rule settings that will need to be modified for the implementation.
| Setting | Description |
| Source location | Location of the files to be loaded. Configured through the Dynamic system settings defined in the SCE installation guide. |
| Source name mask | Defines the standard masked naming convention for files to be picked up. For example: *.edi |
| Service package | The type of file being picked up. The SCE will use the CEXMLFile and CEX12 for the XML and EDI files |
| Service class | The class of the service. The SCE uses X12 for EDI and Claim for XML |
| Service method | The service being invoked on file receipt. For EDI claims, this is the EDIFileService. For XML claims, the following are used:
|
X12 EDI claim file load
The X12 EDI files provide support for de-batching the file prior to the claim being loaded to the SCE. The process for the loading, parsing and de-batching the file is defined below.
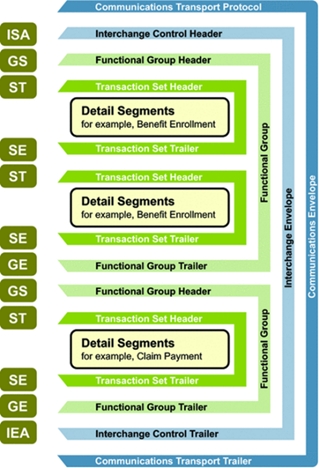
SCE de-batching process and file load
The file listener picks up the file for de-batching and if the ingest file is not corrupted, the X12 de-batch process is initiated. Files to be loaded successfully need to be in a format guided by the appropriate X12 837 specifications. The file details (File ID, Name, Total number of claims) are recorded and if any exceptions or errors are found, they are logged. The file statuses are logged in the PegaX12-Data-Filestatus table. The database table for showing all the exceptions is PegaX12-Data-Exception. The exception table will show the exact exception message, as well as the X12 string where the actual exception occurred. The actual record within the file, where the exception occurred will also be displayed.
File statuses during processing:
| Status | Description |
| In Progress | The file has been picked up for de-batching and loading via the file listener. The status will remain in process until the load has completed or failed. |
| Processed with errors | The file has claims with parsing errors and the N837ClaimError DSS setting is Ignore. In this situation, any claims that have errors are skipped. |
| Partially processed with errors | The file has claims with parsing errors and the N837ClaimError DSS setting is Fail. In this situation, the process will stop, and any claims loaded will remain. Note: if the first claim in the file fails, then the status will be Failed. |
| Failed | All the claims in the file have failed parsing or the file is corrupted |
| Success | All the claims in the file are processed successfully |
During the load of the claims into the N837 data objects, the claims are compared against existing records using the following unique keys:
- EDI control number
- Group ID
- Transaction ID
- Claim type
- Claim ID
If any duplicate instances already exist for the new record being created, then the status for that new record (X12ClaimStatus) will be set to -2 indicating that is a duplicate. Initial successful record statuses are set to 0. The database table for displaying all N837 transactions is PegaX12-Data-N837.
The N837 records with a 0 status are then processed to create claim work objects ready for SCE processing. Any record with a -2 are ignored. Once the claim work object is created successfully, the record status is set to 1. Any errors of records during the work object creation is assigned a status of -1.
N837 claim record statuses:
| Status | Description |
| 0 | Successful creation of the claim as a record, but not yet created as a claim work object for processing |
| 1 | Successful creation of the claim as a work object for processing |
| 2 | Duplicate record with original in error status |
| -1 | Error creating the claim as a work object |
| -2 | Duplicate of another record on the table |
| -3 | Claim work object has been logically deleted from the system. Note: this process is documented in a following section. |
Claims that are successfully loaded as claim work objects are assigned a status of New and ready for the SCE to process them through the appropriate orchestration.
X12 EDI segment handling
The SCE supports multiple interchange control segments (ISA/IEA) within the same file. This could indicate transactions from multiple providers that have been concatenated by an EDI gateway. Within the interchange control segments, the SCE supports a single functional group (GS/GE) and multiple transaction sets (ST/SE).
X12 EDI delimiters
SCE currently handles the following types of ASCII fields to be used as delimiters in the file:
| ASCII Decimal | Character | ASCII Decimal | Character |
| 0 | <NULL> | 33 | ! |
| 1 | <SOH> | 34 | " |
| 2 | <STX> | 35 | # |
| 3 | <ETX> | 36 | $ |
| 4 | <EOT> | 37 | % |
| 5 | <ENQ> | 38 | & |
| 6 | <ACK> | 39 | ' |
| 7 | <BEL> | 40 | ( |
| 8 | <BS> | 41 | ) |
| 9 | <HT> | 42 | * |
| 10 | <LF> | 43 | + |
| 11 | <VT> | 44 | , |
| 12 | <FF> | 45 | - |
| 13 | <CR> | 47 | / |
| 14 | <SO> | 58 | (:) |
| 15 | <SI> | 59 | ; |
| 16 | <DLE> | 60 | < |
| 17 | <DC1> | 61 | = |
| 18 | <DC2> | 62 | > |
| 19 | <DC3> | 63 | ? |
| 20 | <DC4> | 64 | @ |
| 21 | <NAK> | 91 | [ |
| 22 | <SYN> | 92 | \ |
| 23 | <ETB> | 93 | ] |
| 24 | <CAN> | 94 | ^ |
| 25 | <EM> | 95 | _ |
| 26 | <SUB> | 96 | ` |
| 27 | <ESC> | 123 | { |
| 28 | <FS> | 124 | | |
| 29 | <GS> | 125 | } |
| 30 | <RS> | 126 | ~ |
| 31 | <US> | 127 | <DEL> |
X12 837 XML claim file load
Smart Claims Engine can import specific claim files in XML format and process them through the adjudication flow. The types of files that can be processed are:
- Professional Healthcare Claims (837P)
- Institutional Healthcare Claims (837I)
- Dental Healthcare Claims (837D)
Claims for import must be complete and well-formed XML that conforms to the ACS X12 XML format.
Records in the files that fail parsing are stored in the PegaX12XML-Data-Exception table. The file service associated with the claim format saves the claims in a table ready for processing in the SCE. Claims that are ready for processing in the SCE are assigned a status of New.
Claim creation and orchestration execution
The SCE utilizes two methods to support the creating of, and processing of claims in an efficient way. These methods are used to support the creation of claim work objects from the N837 data objects and the processing of new claims through the appropriate orchestration. Out of the box, the SCE provides queue processors to perform these actions, but the system can also be configured to utilize job schedulers.
The SCE uses the DSS setting EnableQPForClaimProcessing to decide which model to utilize. Based on this setting, other configuration items are available for modification in the system configuration page detailed in Core Configurations. When the EnableQPForClaimProcessingflag is True, the queue processors are used. If the flag is False, the job scheduler configuration is enabled for use.
Queue processors
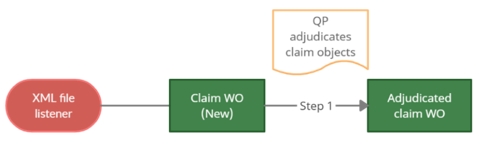
The queue processors (QP) are used in two steps in the EDI intake channel. The first step creates the claim work object from the N837 data instances and the second step processes the claim work object through the orchestration.
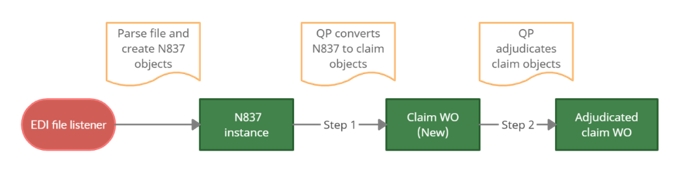
The XML channel just uses the queue processor to process the claim work objects through the orchestration.
N837 to claim work object queue processor
There is one queue processor, CreateClaimWorkObject, and associated activity, QueueX12ClaimWorkObject, which is used to create the claim work objects from the N837 data instances. This processor and activity are configured with the following settings out of the box, the remaining are set to the standard defaults:
QueueX12ClaimWorkObject:
- Type of queue – Dedicated
- Queue processor – CreateClaimWorkObject
- Lock using – Primary page
CreateClaimWorkObject:
- Associated with node type - BackgroundProcessing
- When to process - Immediate
- Number of threads per node - 5
N837 data instances which were unable to be processed can use the Ingest recovery portal and requeued.
Claim processing queue
The claims processing queue is used for claims that are in a New or Pending-Reprocess status. The SCE provides an extension and configuration to create multiple priority queue processors for adjudication against an orchestration. This will enable specific payers or other high priority claims to utilize a different queue processor. The decision table PrioritizeClaimProcessing is provided for this situation. Out of the box, two queue processors are configured:
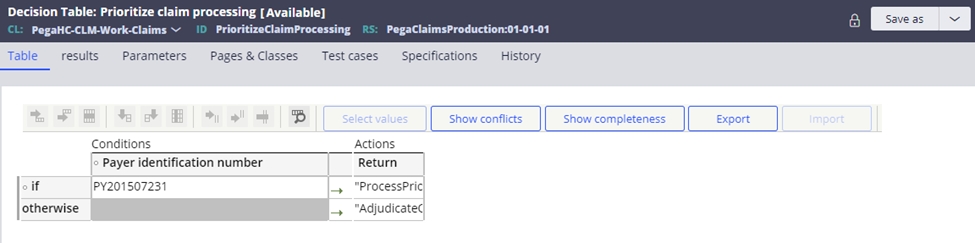
- ProcessPriorityClaim – Queue processor for high priority claims
- AdjudicateClaimWorkObject – Default queue processor for claims processing.
The out of the box configurations for these queue processors are the same as the CreateClaimWorkObject queue processor.
Above mentioned queue processor implementation is applicable for “New” claims and “Pending-Reprocess” claims.
Activities supporting the claims queue processors:
- CreateClaimWOFromN837 – Supports new claims through the EDI channel.
- CreateXMLClaimWrapper – Supports new claims through the XML channel.
- CreateSplitClaimsWrapper – Supports new split claims.
- PrepareClaimForReprocess – Supports claims that are pending reprocessing.
Additional queue processor implementation notes:
- Pega queue processors use Kafka technology and rely on stream nodes in a cluster. It is mandatory to have at least one stream node configured in the Pega cluster. If stream node is not available and system queues a message, the system saves the message in a database and pushes it to Kafka when the stream node is running. The system does not process the messages in a queue until at least one stream node is available. These messages can be viewed in System-Message-QueueProcessor-DelayedItem class instances.
- Items that are failed to process through queue processors can be viewed in broken
queue items from Admin Studio and can be requeued for processing

Job Schedulers
Job schedulers provide another way of loading claims into the SCE for processing. Like the queue processors, there are two steps in the EDI process and one step for XML. The job schedulers will be utilized when the EnableQPForClaimProcessing flag is False. Job schedulers are configured in Admin Studio.
The SCE provides two configuration points for the job schedulers. The first is a decision table to manage the agents and nodes used, and the second is the configuration for the maximum number of job schedulers to be used for that step. Each claim is processed sequentially by each of the nodes configured in the decision table.
- The conversion of N837 data instances is managed by the DetermineX12BatchAgentNumber decision table and the NumberofAgentsN837 dynamic system setting. The job scheduler for the conversion of N837 data instances to claims work objects for processing is the X12BatchEDIProcessor.
- The processing of new claims is managed by the DetermineAdjudicationAgentNumber decision table and the NumberofAgentsforAdjudication dynamic system setting. The job scheduler for the processing of new claims is CE_ProcessNewClaims.
There are a series of settings in the application configuration menu that are used to support the job schedulers. These are found in the Claim Processing Setting section. Note that these settings are only visible if the EnableQPForProcessing flag is false:
| Setting | Description |
| Process claim status list | This defines the claims statuses that are processed with the CE_ProcessNewClaims job scheduler. To add items, select Modify status list, add the new appropriate status, and select Submit. |
| Process Pending-Reprocess claims | This is the setting to resubmit Pending-Reprocess claims through the system. This can be configured for minute, hour, day, or week. Selecting Process now will immediately process these claims. |
| Process recycle claims | This enables claims that are in recycle to be processed immediately, by selecting Process now. Pending-recycle claims will normally be processed based on the recycle configuration in the event code. |
| Process new claims every | This is the setting to submit New claims through the system. This can be configured for minute, hour, day, or week. Selecting Process now will immediately process these claims. |
Field and code validations
The SCE performs a series of validations on the transactions being submitted. If the claim fails to pass these parsing validations, then the transaction will be rejected. In the instance of an EDI claim, the failures will be logged in the Exception list managed through the ingest recovery process.
The SCE uses the field definitions in the data model for the API and the X12 837 specifications for the EDI and XML transactions to perform the validations.
A couple of example validations are listed below:
- Date related validations:
- Date related format – i.e. ABCD is not a valid date/time value.
- RD8 format – the date values submitted are not in the CCYYMMDD-CCYYMMDD format.
- D8 format – the date value submitted is not in a CCYYMMDD format.
- DT Format – the date time submitted is not in a CCYYMMDDHHMM format.
- Field level constraints:
- Field level value list restrictions – i.e. XZ is not a valid US State.
- Field length related restrictions – i.e. MAaa is too long for a US state, the maximum length configured is 2.
- Datatype related restrictions – i.e. ABCD is not a valid integer.
The SCE has a separate portal to identify claims that failed the load and need to be reprocessed. This portal is the Ingest Recovery Process portal.

To find exceptions, select the Exception list to be presented with a list of exceptions that have been logged. You can also search by File name or Exception age.
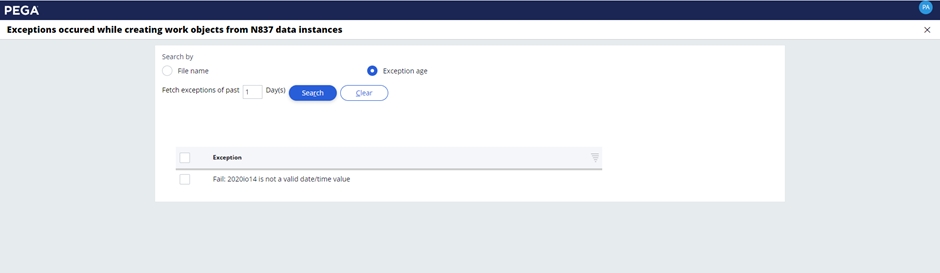
Selecting the exception will display the transactions that set that error and the appropriate file names in the Exception recovery window.
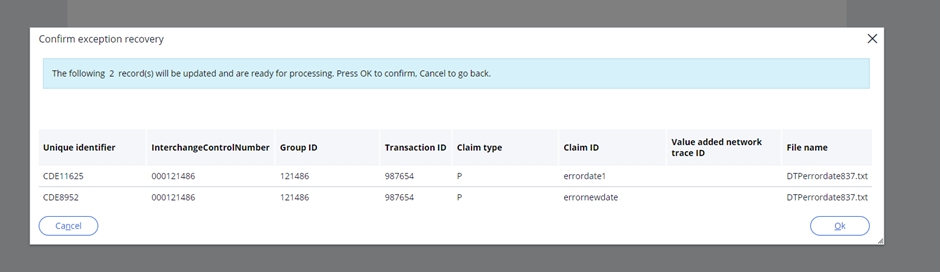
If exceptions are found, or duplicates identified in the files, those files can be checked, corrected, and resubmitted. Once resubmitted, and there are exceptions found, the status of the associated records will be updated to -1 and listed back in the portal. Records reprocessed successfully will be updated to status 1.
There are two main categories of error that can be resolved, and each are handled slightly differently. The first category is a data level exception and the second is a code level exception.
Data level exceptionIn this situation, data in the EDI file is invalid. For example, a date is malformed, or characters are in a numeric field. The exception is listed in the ingest recovery process portal. The file will need to be updated and placed back in the pickup repository for reprocessing. Once the file is processed successfully, the exceptions will no longer be listed.
Code level exceptionsIn this situation, data in the EDI file may be invalid or a local lookup list may need updating. For example, a code submitted in the transaction may not be listed in the field validation list. To resolve this, you would update the field validation list with the missing code. In the exception recovery window, you would select OK and the transaction would be reprocessed. If the code was an invalid code, then the data level exception process would need to be followed and the file appropriately updated and resubmitted.
Previous topic Claim receipts and format Next topic Claim API integration