Performance Overview
Interactive users typically believe that "performance" is synonymous with response time— the number of elapsed seconds that it takes for them to receive an initial reply screen from a system after they submit a form. For many situations, the users are correct: response time is a valid and meaningful measurement of system performance. Slow responses, and response times that are unpredictable, both hurt user productivity.
At a business level, another important measure of performance is throughput — how many completed units of work (orders, customer service requests, investigations) can be processed per minute (or hour, or workday). A system that provides users with excellent response time, but is designed with too many required interactions (for each unit of completed work) may have unacceptably low throughput. For example, in an initial design, assume that completing a certain business transaction that requires 24 interactions (each averaging 30 seconds). If this transaction can be redesigned to require only 18 interactions (with comparable response and user input times), the new design improves user productivity and throughput.
Measures of both response time and throughput can focus on averages, or on peaks (worst case situations), or on thresholds. For example, a performance threshold target might be stated as "ninety-five percent of responses must be received within 5 seconds", whereas the average may be distorted by rare, but very lengthy responses.
What is Performance? | Key Features & Attributes | Terminology | Additional Information
What is Performance?
Highly productive PRPC applications supporting tens of thousands of busy users, millions of work objects, and hundreds of thousands of interactions per hour are in use worldwide. While these show the scale that is possible, achieving such high performance requires adherence to good design and implementation practices. Best results are often achieved through performance analysis and tuning projects that may involve hardware, operating system, network, database, and workstation browser changes, in addition to evolution of the PRPC application.
PRPC offers application designers and system administrators a rich set of tools to identify, analyze, and address potential performance issues, usually exercised in a pre-production setting. These can and should be used throughout the development cycle, not only in reactive situations where performance is discovered to be unsatistifactory. While a few of these tools and techniques require deep technical knowlege about Java or database design, many facilities support "typical" application designers, empowering them to identify and address common sources of potential performance issues. For example, a pop-up alert ![]() can appear immediately after a rule is first executed (typically by the person who created that rule), indicating a potential performance issue.
can appear immediately after a rule is first executed (typically by the person who created that rule), indicating a potential performance issue.
The best way to create a high-performance application is to follow good design and implementation practices throughout the development cycle. Paying attention to performance only late in the cycle or in a remedial or emergency situations can be costly and disruptive.
Many hardware or software monitoring tools are normally disabled, and turned on only for specific periods, because their use affects the system activities being measured, potentially distorting the results or affecting users. However, several important PRPC performance tools are "always on", so no extra performance impact arises by using them.
Key Features & Attributes of Performance
Included in the development methodology are guardrails: advice and best practices that contribute to performance, maintainability, and useabillity. For example, designing your application to promote rule reuse and sharing (that is, to be modular) reduces the number of distinct runtime elements the system must manage and execute. (Modularity has additional benefits, making your application easier to understand and maintain.) User interface testing by untrained users may identify learning or usability obstacles that affect both productivity and performance.
Built-in features help achieve good performance; when necessary for special situations you can bypass these features, but doing so can affect performance:
- Rule warnings — Each time that you save a rule, it is validated. Warnings may appear describing apparent variances from good practices. Certain warnings identify possible performance impacts and are rated by severity (1 to 4). Warnings do not prevent you from saving or executing the rule, but shouldn't be ignored.
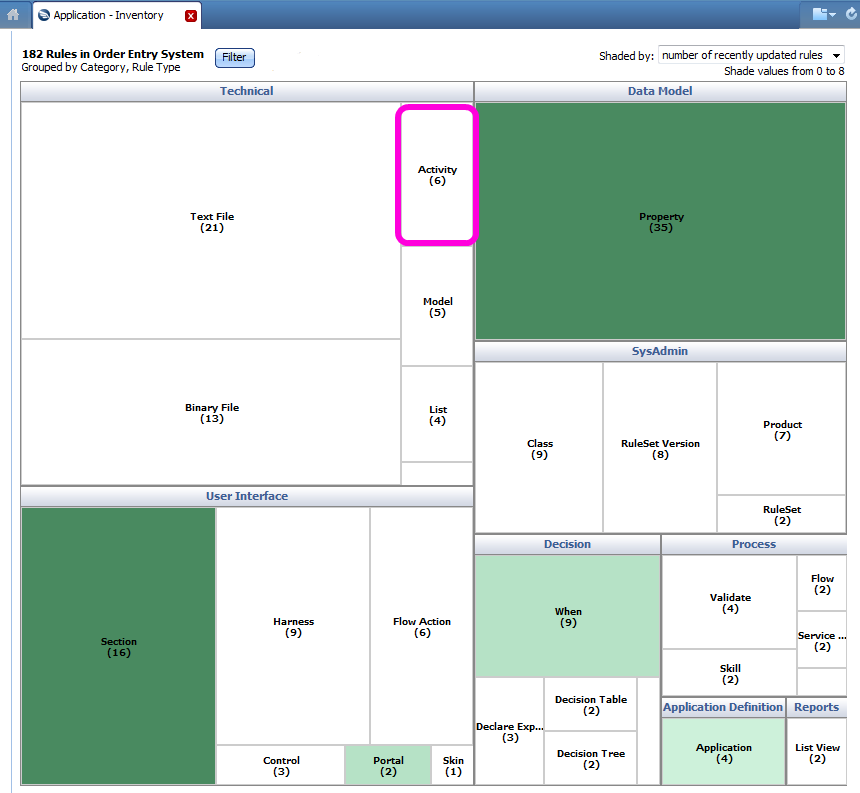
- Appropriate rule types — While activity rules are flexible and powerful, using a decision rule, declarative rule, validation rule or other rule type appropriate to the need, rather than an activity, can improve performance and maintainability. The Order Entry application that is summarized as a heat map display (below) has 182 rules, but only six of them are activities. (The green rectangles reflect the areas of recent rule change. )
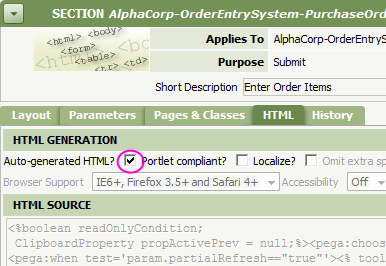 Auto-generated HTML, CSS and JavaScript — User interface rules and wizards (such as harness, section, portal, and control rules) produce high-quality HTML, JavaScript, and CSS. If truly necessary, your application can include custom JavaScript, hand-crafted CSS styles, and hand-crafted HTML, but these can affect browser performance.
Auto-generated HTML, CSS and JavaScript — User interface rules and wizards (such as harness, section, portal, and control rules) produce high-quality HTML, JavaScript, and CSS. If truly necessary, your application can include custom JavaScript, hand-crafted CSS styles, and hand-crafted HTML, but these can affect browser performance.- Generated Java — Many rule type automatically create Java code from information in rule forms. In activities, function rules, and a few other rule types, you can directly enter Java code, but in these cases you assume responsibility for the performance efficiency of that code.
- Generated SQL — Most operations to retrieve or update data in the PegaRULES database use SQL statements generated by PRPC . These are designed to be aware of, and take efficient advantage, of the database schema structure, including indexes, alternate keys, and so on. When truly necessary in unusual, special situations, your application can include hand-crafted SQL statements to augment or bypass generated SQL , but these too can introduce performance issues.
- Alerts —
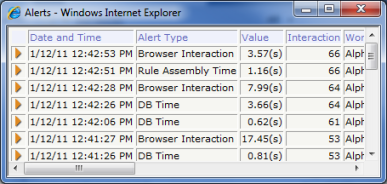 More than 40 built-in alerts and a dedicated log identify individual atomic operations that were costly in terms of elapsed time, quantity of data processed, CPU time, JVM memory, or other dimensions. For example, the DB Time alert (PEGA0005) indicates that a request to the PegaRULES database required more than half a second (500 milliseconds) for data to be returned to the server. In a development environment, a fraction of the alerts are usually transient and arise through tasks that will not occur at runtime in production. However, many alerts provide early warning that a costly rule or rules were recently executed. While application designers can choose to ignore these alerts, or can effectively disable them through settings changes, alerts can be valuable early clues about rules that will affect overall performance.
More than 40 built-in alerts and a dedicated log identify individual atomic operations that were costly in terms of elapsed time, quantity of data processed, CPU time, JVM memory, or other dimensions. For example, the DB Time alert (PEGA0005) indicates that a request to the PegaRULES database required more than half a second (500 milliseconds) for data to be returned to the server. In a development environment, a fraction of the alerts are usually transient and arise through tasks that will not occur at runtime in production. However, many alerts provide early warning that a costly rule or rules were recently executed. While application designers can choose to ignore these alerts, or can effectively disable them through settings changes, alerts can be valuable early clues about rules that will affect overall performance.
Describing performance goals
Because performance has many dimensions, agreement on goals and measures of success is an important first step in a performance improvement effort. Some changes are "win-win" — for example, reducing the number of rows retrieved from the PegaRULES database also reduces the number of bytes sent over the network, and probably also reduces the amount of memory needed to hold the data on the server.
But other changes involve tradeoffs, reducing demand for one type of resource (or increasing supply) but adding to demand for another type. Such changes may improve performance by one measure but hurt performance when assessed a different way.
Likewise, identifying the important bottlenecks and opportunities may take research. Improving one lightly used task so that it is 200% faster is impressive but may have minor overall impact compared with a 2% improvement in a vital, heavily used task.
Typically, JVM memory and database operations are the performance-limiting factors in J2EE business applications such as PRPC ; network, workstation, and CPU resources are less commonly important factors. However, every system is different, and merits study so that the effort focuses on objectives that are worthwhile.
While advanced performance analysis requires deep technical skills to interpret and act on typically large volumes of data, PRPC provides common-sense, easy-to-use alerts, logs, and tools that help every application designer understand the performance impacts of the rules they create.
Important Terminology
These terms are relevant to understanding the performance of a PRPC system.
Alert — A message indicating that a performance threshold has been exceeded by a specific rule execution. In a development system, alerts can appear interactively at the time they occur. Alerts are recorded in a text long file, which identifies the alert type, the operator, date and time, the rule that likely caused the alert, and performance results (elapsed time, bytes, CPU time, and so on).
 Application Preflight report — This tool summarizes the rules in an entire application that contain warnings, presenting the results as bar charts and pie charts.
Application Preflight report — This tool summarizes the rules in an entire application that contain warnings, presenting the results as bar charts and pie charts.
You can interact with the charts to drill down to the individual rules that contain the warnings, and use your understanding of the application structure to consider whether the rule is acceptable as is or should be reworked to eliminate the warning.
For example, a warning occurs if a list view rule displays, in a column, a property value that is not an exposed column in the PegaRULES database table that holds the data being reported on. This list view rule executes correctly, but will perform better if the properties it displays are each individual database columns. If the report is run only rarely, changing the database table structure (to eliminate the warning) may not be worthwhile; if the report runs often, exposing the properties as columns may improve overall performance.
Autonomic Event Services — Another product offering, AES, is a PRPC application that monitors and consolidates alerts from one or more target Process Commander systems, to identify patterns and trends in the generated alerts and to suggest priorities and specific steps for remedial attention.
 AES provides dozens of charts and tabular displays of data to system managers. For example, the AES chart below shows the peak number of unique users for a system by day, with separate lines for interactive (browser) users, background agents, and other batch users.
AES provides dozens of charts and tabular displays of data to system managers. For example, the AES chart below shows the peak number of unique users for a system by day, with separate lines for interactive (browser) users, background agents, and other batch users.
Autogenerated HTML — By default,PRPC produces HTML, CSS and JavaScript code when you save a rule that supports the user interface of your application. If you bypass or disable auto-generation, you can directly enter HTML, styles, and JavaScript, but then take responsibility for the performance (and integrity) of that code.
Blob — Each row of most tables in the PegaRULES database contains a column that has a special, compressed copy of the data for that row. Certain server operations require that this value be copied to the server, unpacked, updated, repacked, and updated on the database; these operations can be costly if the blob values are large. Performance tuning includes tactics to discover and eliminate such operations.
Caching — PRPC automatically maintains a number of caches; most are self-regulating and do not require frequent monitoring or adjustment. However, in some production settings, increasing the maximum size of a cache may help performance; in others, decreasing the size (making memory available to support other activities) may help performance.
Clipboard — An internal memory space dedicated to each user (requestor), the size of a user clipboard grows and shrinks over time. Because all user clipboards collectively typically add up to a significant portion of the available memory provided by the Java Virtual Machine, it is important to minimize the size of each user's clipboard, by deleting parts ("pages") after they are no longer needed.
Database Trace — A tool that provides a comprehensive and detailed log of accesses to the PegaRULES database. The log shows the SQL statement and the elapsed time for each operation, and whether a rule was found in the rule cache.
Exposed columns — Columns in a database table other than those that form the key to a row, and not the Blob column. Each exposed column contains a single property value. SQL operations such as SELECT queries can operate efficiently and directly on these column values. Presenting data as a column speeds up retrieval operations that depend on that column, but involves trade-offs. Exposing too many columns makes the row larger and can slow update operations.
Garbage collection — An internal operation of the Java Virtual Machine to reclaim memory space no longer needed by individual requestors.
Guardrails — A collection of good design practices and practices to avoid, to promote performance, maintainability and reuse.
 Performance Analyzer tool — An always-on data collection facility providing summary and detailed performance statistics about each user interaction. Detailed statistics cover elapsed time, CPU time, bytes of data retrieved from the database, Blob operations, and other data. This tool is "always on"; there is no added cost for data collection.
Performance Analyzer tool — An always-on data collection facility providing summary and detailed performance statistics about each user interaction. Detailed statistics cover elapsed time, CPU time, bytes of data retrieved from the database, Blob operations, and other data. This tool is "always on"; there is no added cost for data collection.
Performance Profiler gadget — A landing page gadget that produces a detailed trace of performance information about the execution of activities, when condition rules, and model rules executed by your requestor session. (Unlike the Performance Analyzer, this tool does introduce extra costs when run, as it produces extensive, detailed output.)
Rules Assembly — A one-time on-demand internal process to create ("assemble") the Java code needed for a specific rule executed for the first time in a specific user context. The second and later times the same rule is executed, assembly is then not necessary. This "performance penalty" is transient, but can affect user experience briefly after system startup when new rules are introduced into an application (or rules are frequently changing, as in a development environment.) Also called "First-use assembly".
Static Assembler — A command-line facility that can assemble all rules in a specific RuleSet in batch mode, to eliminate the interactive delays due to rules assembly processing.
System Management Application — A Java program that allows a systems administrator to examine logs, monitor system health, and make changes to one or more separate PRPC servers.
Additional information
![]() Ten Guardrails to Success | January, 2009
Ten Guardrails to Success | January, 2009
![]() How to use the Static Assembler utility to pre-assemble the rules in an application | July, 2010
How to use the Static Assembler utility to pre-assemble the rules in an application | July, 2010
![]() About Autonomic Event Services (AES) - Enterprise Edition | January, 2010
About Autonomic Event Services (AES) - Enterprise Edition | January, 2010
![]() Understanding rule warning messages | September, 2008
Understanding rule warning messages | September, 2008
![]() Ten best practices for successful performance load testing | November, 2008
Ten best practices for successful performance load testing | November, 2008
![]() Understanding caching | September, 2011
Understanding caching | September, 2011
![]() Designing and Building for Performance | March, 2008
Designing and Building for Performance | March, 2008
Previous topic Performance Next topic Designing and Building for Performance