Best practices for Stream service configuration
This content applies only to On-premises and Client-managed cloud environments
Follow these guidelines for the recommended configuration of the Stream service in your system.
Expected throughput
Data throughput depends on the number of nodes, CPUs, and partitions, as well as the replication factor and bandwidth
Review the results of tests on three running stream service nodes on machines with the following configuration:
- CPU cores: 2
- Memory (GB): 8
- Bandwidth (Mbps): 450
- Number of partitions: 20
- Replication factor: 2
The following table shows the test results for writing messages to the stream (producer):
Producer throughput – test results
| Records | Record size (bytes) | Threads | Throughput (rec/sec) | Average latency (ms) | MB/sec |
| 5000000 | 100 | 1 | 83675 | 2.2 | 8.4 |
| 5 | 172276.1 | 11.9 | 17.2 | ||
| 10 | 216682.8 | 40.4 | 21.7 | ||
| 100 | 1 | 32967.7 | 5.1 | 33 | |
| 5 | 53033.7 | 48.6 | 53 | ||
| 10 | 49861.7 | 174.3 | 49.8 | ||
| 100 | 1 | 76812.1 | 2.4 | 7.7 | |
| 5 | 165317.4 | 13.3 | 16.5 | ||
| 10 | 203216.3 | 46.1 | 19.38 | ||
| 1000 | 1 | 35865.7 | 4.8 | 35.9 | |
| 5 | 52456.7 | 41.9 | 52.4 | ||
| 10 | 50266.1 | 158.8 | 50.3 |
The following table presents the test results for reading messages from the stream (consumer):
Consumer throughput – test results
| Records | Record size (bytes) | Threads | Throughput (rec/sec) | MB/sec |
| 5,000,000 | 100 | 1 | 120673.8 | 12 |
| 5 | 150465 | 15 | ||
| 10 | 143395.3 | 14.3 | ||
| 1,000 | 1 | 54128.4 | 54.1 | |
| 5 | 55903.3 | 55.9 | ||
| 10 | 54674.5 | 54.7 |
Disk space requirements
By default, the Kafka cluster stores data for 60 hours (2.5 days). You can change the
retention period for specific stream categories by modifying the
services/stream/category/retention/categoryName
property in the prconfig.xml file, where
categoryName can have one of the following values:
datasetdecisioningqueueprocessorsystem
For example, you can set the retention period for streams in the QueueProcessor
category by using the following property:
services/stream/category/retention/queueprocessor.
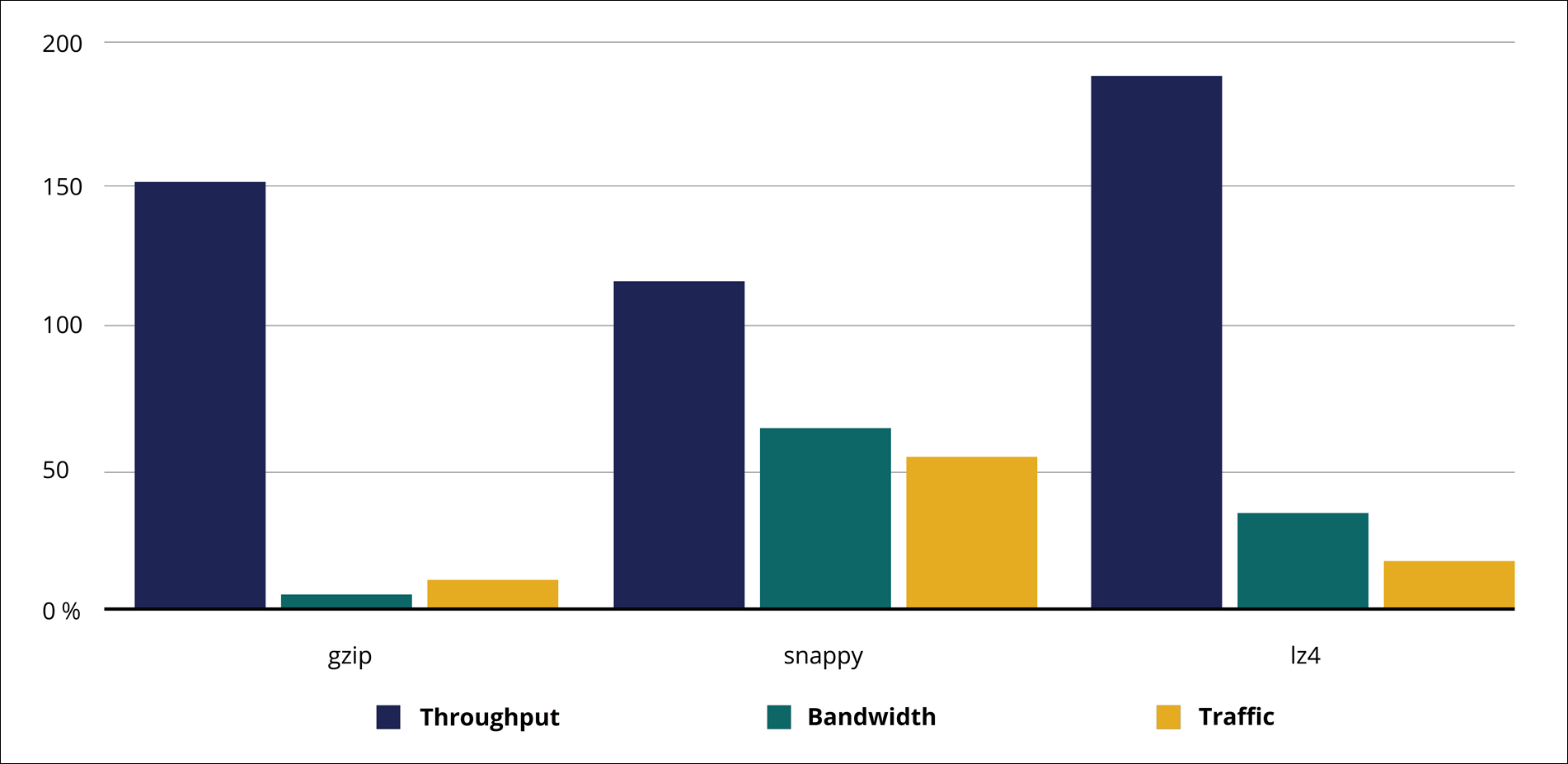
Compression
Depending on your needs, you can choose data compression using one of the algorithms that Kafka supports: gzip, Snappy, or LZ4. Consider the following aspects:
- Gzip requires less bandwidth and disk space, but this algorithm might not saturate your network while the maximum throughput is reached.
- Snappy is much faster than gzip, but the compression ratio is low, which means that throughput might be limited when the maximum network capacity is reached.
- LZ4 maximizes the performance.
Review the following table and diagram with throughput and bandwidth usage per codec:
Throughput and bandwidth per codec (%)
| Codec | Throughput % | Bandwidth % |
| None | 100 | 100 |
| Gzip | 47.5 | 5.2 |
| Snappy | 116.3 | 64.1 |
| LZ4 | 188.9 | 34.5 |

Previous topic Configuring the Stream service Next topic Monitoring the Stream service