Importing adaptive models to another environment
This content applies only to On-premises and Client-managed cloud environments
You can import trained Adaptive Decision Manager (ADM) models from your production environment to a simulation environment. Synchronizing both environments is useful when you want to run scenarios in your simulation environment and apply the most up-to-date models. Adaptive models in the production environment are constantly processing data and self-learning. By importing these models to your simulation environment, you ensure that the scenarios that you run yield relevant and accurate results.
- In the source environment, export the pyADMFactory data
set.This data set is a database table that contains all the adaptive model instances in your system. For more information, see Exporting data into a data set.
- Log on to the target environment and perform the remaining steps there.
- On the Services landing page, on the Adaptive Decision
Manager tab, decommission all ADM nodes by selecting the
appropriate action from the Action menu.
Decommissioning a node 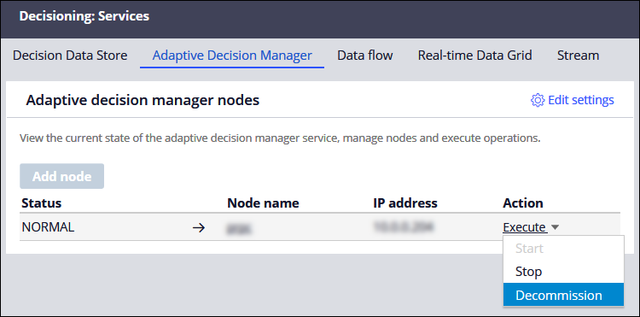
- Open the pyADMFactory data set, and then from the Actions menu, select Run.
- In the Run Data Set dialog box, from the
Operation list, select
Truncate.
Running a data set 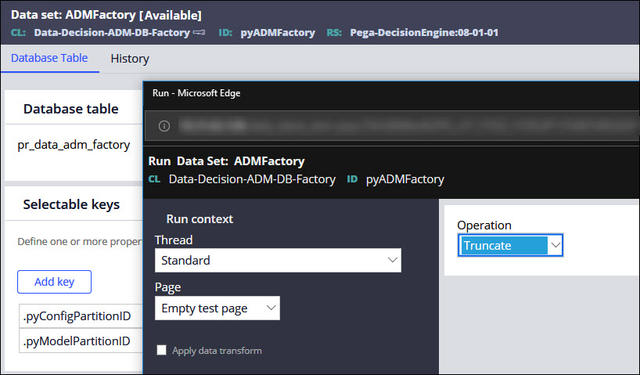
- If the target system has any models that report data in the following tables,
prevent inaccurate reports by manually truncating the following tables:
- pr_data_dm_admmart_mdl_fact
- pr_data_dm_admmart_pred
- Connect to a Cassandra database on a Decision Data Store node.For more information, see Connecting to an external Cassandra database.
- Remove any ADM (response) data that may cause a conflict with the source data
by using the following CQL commands:
- drop keyspace adm_commitlog
- drop keyspace null_adm (if present)
- drop keyspace adm (if present)
- Import the pyADMFactory data set from the source
environment.For more information, see Importing data into a data set.
- Recommission all ADM nodes.The first node that you recommission creates scoring models from the imported factory data. For more information, see Connecting to an external Cassandra database.
Previous topic JSON file structure for historical data Next topic Adaptive models monitoring